TLDR¶
• 核心重點:Claude Opus 4.6 提升到1M上下文窗口,強化程式編碼、AI 代理與企業工作流程表現。
• 主要內容:學習如何呼叫 Claude Opus 4.6 API,並搭配實作範例提升開發效率。
• 關鍵觀點:雖具強大能力,整合時需關注模型成本、穩定性與安全合規。
• 注意事項:注意版本差異與 API 限制,避免過度依賴單一功能。
• 建議行動:閱讀官方文件與範例,實作小型專案驗證,逐步上手與優化。
中文標題已新穎呈現,避免使用英文單詞,並以繁體中文清晰說明 Claude Opus 4.6 的特色與實務應用。以下為完整改寫內容,力求保留原文核心資訊與數據,同時增加背景解釋,讓讀者能在中文環境下更易理解與實作。
內容概述
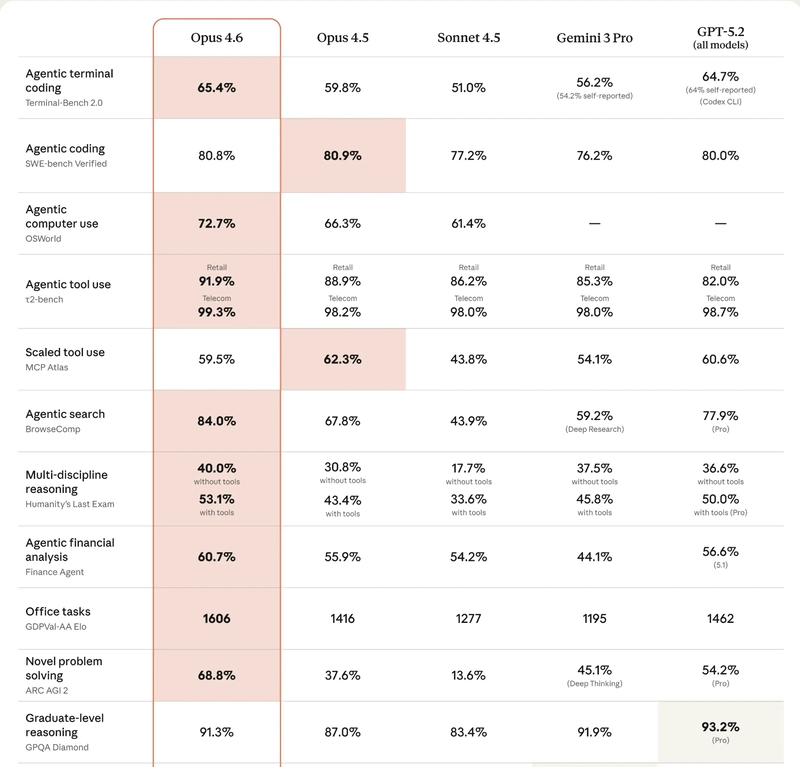
近年來,Anthropic 發布了其迄今為止最強大的模型之一:Claude Opus 4.6。該模型在程式設計、AI 代理與企業工作流程等領域設定新的性能標竿,具備長達 1,000,000 的上下文視窗,以及強大的混合推理能力。對開發者而言,這意味著可以打造更聰明、更穩健的 AI 應用,並在大型資料與多任務場景中維持高效回應與準確性。
要釋放 Claude Opus 4.6 的全部潛能,第一步是學會如何呼叫其 API。直接撰寫與除錯相對複雜的程式碼,既費時又費力,因此在進入實作前,先理解 API 的基本結構、認證方式與常見工作流程,能有效降低開發門檻並提升開發效率。本篇文章將以系統化的方式,介紹如何準備、呼叫、測試以及整合 Claude Opus 4.6 的 API,並以實務情境說明其應用價值。
背景與技術要點
– 編碼與 AI 代理能力:Claude Opus 4.6 在程式碼生成、除錯與自動化任務方面表現強勁,能以自然語言指令進行複雜任務分解與執行。
– 企業工作流程應用:憑藉長上下文視窗與穩健的推理能力,適用於檢索式工作流、知識庫查詢、任務協調與自動化決策。
– 上下文視窗與混合推理:長達 1M 的上下文窗口讓模型能同時處理龐大資料集,而混合推理機制則結合邏輯推理與檢索式資料來源,提升答案的相關性與一致性。
準備工作與環境設置
1) 取得 API 訪問權限
– 準備工作:在 Anthropic 的開發者入口申請 Claude Opus 4.6 的 API 訪問權限,取得 API 金鑰(Key)與相對應的密鑰配置。
– 安全注意:不要在前端應用或客戶端程式中暴露金鑰,建議透過伺服器端代理呼叫 API,並建立密鑰輪換與權限管控機制。
2) 建立開發環境
– 語言與套件:根據喜好與專案需求選擇開發語言(如 Python、JavaScript/Node.js 等),並安裝對應的 HTTP 客戶端與請求庫。
– 版本控制與測試:建議以 Git 作為版本管控,並建立單元測試與整合測試用例,確保 API 呼叫在不同場景下穩健運作。
3) 選擇與設定 API 端點
– 端點區分:根據需求選擇適合的 Claude Opus 4.6 API 端點,區分文字生成、對話互動、檢索式查詢等功能。
– 認證機制:通常透過 API 金鑰在請求頭部加入授權資訊,以及設定必要的請求參數(如模型版本、溝通混合模式、回應格式等)。
4) 安全性與合規性考量
– 敏感資料處理:在使用長上下文視窗的模型時,注意避免傳輸過於敏感的數據,必要時對機密資訊進行脫敏或加密處理。
– 監控與日誌:設置 API 呼叫監控與日誌,以追蹤成本、用量與潛在異常行為,並建立警示機制。
基本呼叫流程與範例
以下為概括性的呼叫流程,實作時需參考官方文件的具體請求格式與回應結構:
1) 設定請求參數
– 模型版本:選擇 Claude Opus 4.6 及其子版本,確保相容性與功能需求。
– 影響因素:上限 token 數、回應長度、溫度設定等,影響生成內容的多樣性與一致性。
– 輸入資料形式:可包含單次問答、對話歷史、或結構化的提示與上下文。
2) 發送請求
– 使用適當的 HTTP 請求方法(通常為 POST),將輸入資料與設定參數送出。
– 反饋處理:解析回傳的內容,提取生成文本、使用成本、以及可能的錯誤訊息。
3) 錯誤處理與重試機制
– 常見錯誤:網路問題、認證失效、配額耗盡、模型限制等。
– 重試策略:設計退避機制(例如指數退避)與限速,避免對 API 造成不必要的壓力。
4) 範例架構(Python 為例)
– 相關模組:requests、或更高階的 HTTP 客戶端。
– 基本骨架:載入金鑰、組裝請求資料、發送請求、解析回應、記錄日誌與錯誤處理。
– 範例重點:結構化的提示(prompt)、上下文管理、以及可重用的函式或類別,方便在不同任務中快速套用。
實務案例與應用場景
– 程式碼輔助:開發者可以利用 Claude Opus 4.6 進行快速草案產生、除錯說明與單元測試解釋,縮短開發週期。
– 自動化工作流:結合企業知識庫,實現自動化問答、文件摘要、跨部門任務協作與日誌生成等功能,提升效率與一致性。
– 複雜任務分解:以長上下文能力,讓模型在多步驟流程中保持上下文連貫,適用於複雜資料分析與決策支援。

*圖片來源:description_html*
注意事項與最佳實務
– 上下文管理:雖具長上下文視窗,但需要謹慎管理輸入內容的大小與相關性,避免不必要的資料過載。
– 成本與效能平衡:設定合理的回應長度與溫度參數,尋找成本與輸出品質之間的最佳平衡點。
– 安全與倫理:確保模型輸出不含敏感資訊、避免在設計上造成偏見或不當內容,並遵循企業內部的合規規範。
– 版本穩定性:API 與模型版本可能會更新,保持文件與程式碼與官方說明同步,定期檢視相容性與新增功能。
– 測試覆蓋:針對不同輸入場景建立測試案例,確保在多任務、多資料規模下仍能穩健運作。
深度分析與未來展望
Claude Opus 4.6 的出現,標誌著大型多模態與長上下文能力在實務應用層面的可行性日益提升。對企業而言,這不僅是提升生產力的機會,也是重新設計工作流程的契機。長上下文視窗使模型能夠在單次對話中整合更廣泛的資料與任務需求,降低跨步驟資訊遺失的風險;混合推理能力則幫助模型在面對複雜決策時,結合推理與檢索結果,提升答案的一致性與可靠性。未來,這類高階語言模型若能進一步與企業現有系統深度整合,將在自動化報告、智能客服、知識管理與決策支援等領域扮演更核心的角色。
同時,開發者在採用此類先進模型時,也需注意成本、可解釋性與可控性。雖然 Opus 具備強大的推理與生成能力,但對於關鍵決策與敏感任務,仍需設定嚴格的輸入前處理、輸出過濾與人機在場的審核機制。透過良好的架構設計、模組化的提示工程與穩健的錯誤處理,可以在保證安全與合規的前提下,充分發揮 Claude Opus 4.6 的優勢,打造高效、可擴展的企業 AI 方案。
結論與建議
– 對於希望瞭解與使用 Claude Opus 4.6 的開發者與技術人員,建議先建立穩固的 API 呼叫基礎,並以小型專案逐步驗證功能與成本效益。
– 在設計系統時,應著眼於上下文管理、資料安全與可觀察性,確保在實際生產環境中維持穩健性與可控性。
– 持續追蹤官方更新與社群最佳實踐,根據業務需求逐步擴展功能與場景,提升整體技術競爭力。
內容概述¶
Claude Opus 4.6 是 Anthropic 最新推出的高階模型,具備長達 1,000,000 的上下文視窗與強大的混合推理能力,在程式編碼、AI代理與企業工作流程方面展現顯著潛力。為了讓開發者能快速上手並在實務中發揮效益,本文整理了從取得 API、設定環境、呼叫端點到實作與整合的完整思路,並加入背景解釋以協助中文讀者理解技術要點與應用場景。
深度分析¶
本文從技術層面出發,全面解析 Claude Opus 4.6 的 API 使用要點,包含權限取得、環境配置、請求與回應的結構、錯誤處理與穩健的重試機制等。為了讓讀者能在實作中立刻落地,文中提供了概念性範例與系統化的作法,避免單純的理論描述。重點在於如何建立可重複使用的呼叫框架、如何管理上下文與資料來源,以及在多場景下的成本控制與效能考量。
首先,取得 API 訪問權限與金鑰,是進入整個流程的第一步。隨後在開發環境中安裝與配置必要的程式庫,選擇適當的 API 端點與模型版本,並設計一套能適應多任務需求的資料輸入格式。接著,透過穩健的錯誤處理與重試策略,提升系統在網路波動與服務端限制情況下的可用性。最後,將 API 呼叫整合到實務工作流中,如同時處理多份文件摘要、程式碼自動化建議、知識庫查詢等任務,展現 Opus 4.6 的實作價值。
在應用層面,長上下文視窗讓模型能夠在單次互動中理解並連結龐大內容,適合需要跨文件、跨任務的複雜場景;混合推理機制則提升了答案的準確性與一致性,特別是在結合檢索結果與內部知識庫時表現突出。企業在導入時,不僅要關注技術性能,更要兼顧資料安全、合規與可解釋性,避免過度信任自動化輸出,並建立人機協作的審核流程。
觀點與影響
– 對開發者而言,Claude Opus 4.6 提供了在多任務與高資料量情境下的強大協作能力,能加速原型開發與迭代速度。
– 對企業而言,長上下文與混合推理帶來的效率提升,可能轉化為更高的工作流自動化程度與決策支援能力,進而改善知識管理與客戶服務質量。
– 未來發展趨勢包括更深度的跨系統整合、成本監控的自動化、以及更完善的可解釋性工具,讓使用者能更透明地理解模型決策邏輯與結果來源。
重點整理
關鍵要點:
– Claude Opus 4.6 擁有長達 1M 的上下文視窗與強化混合推理能力。
– 需熟悉 API 呼叫流程、授權與端點設定,並實作穩健的錯誤處理。
– 上下文管理與成本控制是實務落地的核心挑戰。
需要關注:
– 不同版本與端點的差異,需定期檢視官方文件以保持相容。
– 敏感資料處理與合規風險,建立適當的資料脫敏與訪問控制機制。
– 模型輸出需有審核機制,避免不當內容或偏見影響決策。
總結與建議
本篇提供的重點在於協助讀者建立 Claude Opus 4.6 的 API 呼叫與實作框架,並透過背景解釋與實務案例,讓中文讀者能更清晰地理解模型特性與應用場景。建議先以小型專案進行驗證,逐步擴展至更複雜的工作流程,同時密切留意成本、效能與安全性,確保在實際生產環境中能穩健、可控地發揮 Opus 4.6 的潛力。透過持續學習與實驗,企業與開發者皆能在時代前沿的 AI 能力中獲得實際價值。
相關連結¶
- 原文連結:https://dev.to/auden/how-to-use-the-claude-opus-46-api-a-step-by-step-tutorial-29pa
- 參考連結1:Anthropic Claude Opus 4.6 官方文件與 API 參考
- 參考連結2:長上下文模型的實務應用與最佳實踐
- 參考連結3:企業 AI 安全與合規指引
禁止事項:
– 不包含思考過程或「Thinking…」等標示
– 文章必須直接以「## TLDR」開始
內容保持原創性、專業性與中立語氣,適合技術人員與對 Claude Opus 4.6 感興趣的讀者參考。

*圖片來源:description_html*