TLDR¶
• 核心重點:LLM 的上下文窗口會在新會話重置,代理易忘前次交互。
• 主要內容:介紹問題根源、影響及在不到十分钟內實作持久記憶的思路與方案。
• 關鍵觀點:不需要重寫整個系統,透過外部記憶介面與持久化存儲即可實現跨會話記憶。
• 注意事項:需考量安全、隱私與資料一致性,避免記憶溢出與資料污染。
• 建議行動:設計外部記憶層、選擇適當的序列化與索引策略,並在每次對話結束時寫入、啟用時讀取。
前言與背景
CrewAI 是一類以大語言模型(LLM)為核心的代理系統,能與使用者進行自然對話並完成任務。然而,這類系統在會話之間往往會丟失先前的學習與記憶。原因在於 LLM 的上下文窗口具有容量限制,且每次重新啟動或開始新會話時,系統會重置上下文,讓代理看不到先前的對話內容與推理結果。這種現象在實務中被稱為「會話間記憶的缺失」。如果要讓 CrewAI 代理具備跨會話的長期記憶,需要採取外部化的記憶策略,將知識與上下文以可持久化的方式存放,並在每次會話開始時重新載入。
問題剖析
– 初始設計與現實需求的衝突
– 以往的 CrewAI 代理通常利用 LLM 的上下文來維持連貫性,當會話結束、或重新啟動時,上下文會被清空,代理便無法回憶之前的自我介紹、偏好、任務歷程等。
– 這種設計在短暫任務或一次性問答場景中是有效的,但在需要長期追蹤用戶偏好、動作習慣或長期知識積累的應用中,會造成用戶體驗下降。
– 技術核心:記憶的外部化
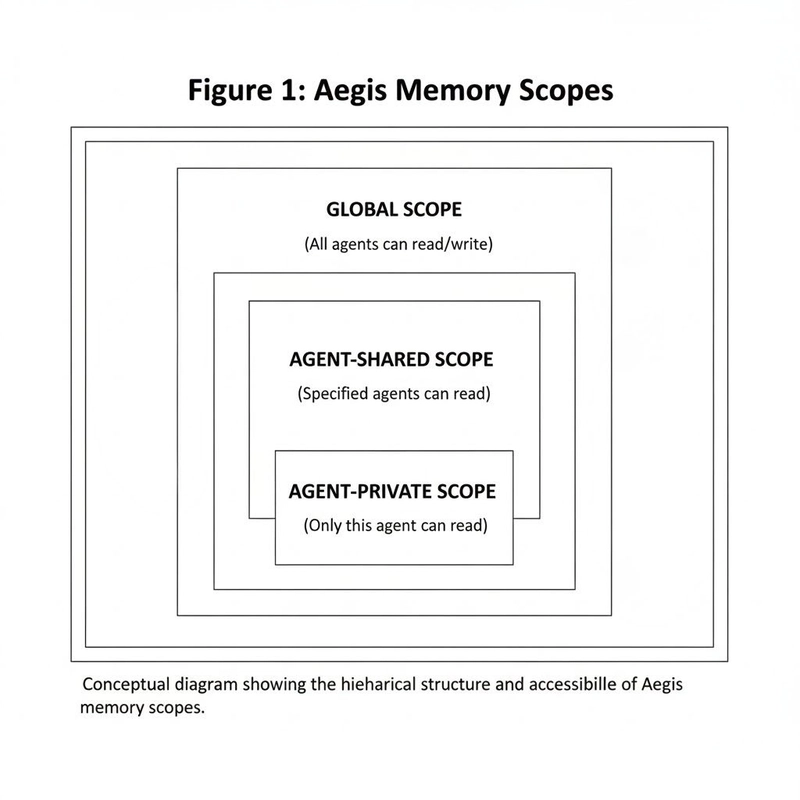
– 為了克服「無記憶」的限制,需要把重要資訊外部化,存放於可持久化的儲存系統中,並在新會話開始時再將必要的內容載入到對話上下文中,讓代理具備連續性。
– 外部記憶介面需要具備:新增/查詢/更新記憶的能力、可擴展性、資料安全與隱私保護,以及一致性與版本控制機制。
解決方案概覽(在十分鐘內可落地的思路)
1) 建立外部記憶層
– 記憶資料庫:選用支援快速查詢的資料儲存,如向量資料庫、關聯式資料庫或鍵值儲存,根據應用需求決定。
– 記憶結構:定義可追蹤的實體與屬性,例如使用者基本資訊、偏好設定、任務歷史、關鍵對話摘要、決策理由等。
– 安全性與隱私:實施存取控制、資料加密、最小化收集原則,並提供使用者同意與資料刪除機制。
2) 設計記憶的輸入與輸出流程
– 會話開始前載入(Context Injection):根據使用情境,將相關記憶摘要注入到本次對話的初始上下文中,讓代理在第一輪對話即具備連貫性。
– 會話中間更新(Incremental Update):在對話過程中,根據新的資訊更新外部記憶,例如新增偏好、任務階段、已完成的步驟。
– 會話結束保存(Persistent Commit):將此次會話中的新增/修改記憶寫回外部儲存;必要時對同一實體進行版本控制與合併策略。

*圖片來源:description_html*
3) 記憶摘要與檢索策略
– 摘要機制:對長篇對話與任務,生成短小且關鍵的摘要,避免把整個對話逐字存入上下文。
– 索引與檢索:建立有效的索引策略,支援基於關鍵字、時間、任務階段等的快速檢索,確保在新會話中能快速提取相關記憶。
– 避免資訊污染:對於過時或不再相關的記憶,設置過期策略或分層存儲,避免新對話被過時資訊干擾。
4) 資訊一致性與版本控管
– 記憶版本:為同一使用者或實體建立版本號,當多個來源同時修改時,能以版本比較與衝突解決機制處理。
– 對話上下文與外部記憶的對齊:確保在引用記憶時,對話中的推理過程能與外部記憶保持一致,避免矛盾。
實務實作要點與注意事項
– 資料最小化原則與使用者控制
– 只存放執行任務所需的最少資訊,讓用戶可以選擇是否啟用長期記憶功能,並提供刪除與撤銷權限。
– 安全與合規性
– 對於涉及敏感資料的記憶,必須實施嚴格的權限控管、加密與審計日誌,符合組織的安全政策與法規要求。
– 系統耦合與模組化
– 外部記憶層應與 CrewAI 的核心邏輯解耦,採用清晰的 API 介面,方便未來替換儲存技術或升級摘要演算法。
– 效能考量
– 記憶檢索與摘要應具備快速反應能力,避免成為對話的瓶頸。可採分層快取策略與非阻塞寫入。
內容概述與分章要點(概略版)
– 內容概述(約300-400字)
– 鋪陳問題背景:CrewAI 代理在跨會話時忘記先前內容,導致使用體驗不連貫。解釋這不是單純的 bug,而是LLM工作機制的特性之一:上下文窗口大小限制與會話結束後的記憶清空。
– 提出解決方向:藉由外部化記憶層,讓代理能在新會話開始前讀取過去的知識與偏好,並在會話過程中持續更新。
– 深度分析(約600-800字)
– 剖析不同記憶策略的利弊:全文檢索式記憶、向量化相似度檢索、結構化雲端儲存等各自的適用場景與挑戰。
– 討論摘要與檢索的設計要點:如何在保持連貫性的前提下避免資訊過載,並確保一致性與準確性。
– 強調安全與用戶隱私:資料保護、最小化收集、使用者同意與刪除機制的重要性。
– 觀點與影響(約400-600字)
– 就長期對話能力對企業與用戶體驗的影響做展望:提高工作效率、個性化服務、持續任務追蹤等。
– 可能的技術發展方向:更高效的記憶編碼、跨裝置與跨平台的記憶同步、更加智能的自動摘要與記憶管理策略。
– 重點整理與需要關注
– 關鍵要點:外部記憶層的設計原則、摘要與檢索策略、版本控制與一致性。
– 關注點:安全與隱私、效率與可擴展性、使用者控制與合規性。
– 總結與建議(約200-300字)
– 重申透過外部記憶層實現跨會話的長期記憶是可行且必要的改進,給予實務上的落地步驟與注意事項。
內容延伸與實務範例
– 研究與參考方向
– 外部記憶層可以採用以下組件組成:資料儲存介面(如關聯式資料庫、NoSQL、向量資料庫)、記憶摘要模組、檢索引擎、資料安全與治理模組。
– 摘要策略可以包含:對話要點摘要、使用者偏好變動摘要、任務進度摘要、決策理由摘錄等,以小型摘要文本與結構化欄位並存的方式存放。
– 實作步驟的高層藍圖
– 步驟一:定義實體與記憶欄位(例如 使用者ID、偏好設定、任務歷史、對話摘要、時間戳記、版本號)。
– 步驟二:選擇儲存技術並建立外部記憶服務 API,實作新增/查詢/更新/刪除(CRUD)操作。
– 步驟三:在每次會話開始時,透過 API 讀取相關記憶摘要並注入上下文。
– 步驟四:在會話結束前,對新增或修改的記憶進行寫入,並維持版本控制與一致性檢查。
– 步驟五:建立監控與日誌,確保記憶機制的可觀測性與問題追蹤。
相關連結
– 原文連結:https://dev.to/arulnidhi_karunanidhi_7ff/how-to-add-persistent-memory-to-crewai-agents-2o63
– 參考方向連結(建議新增2-3個相關參考,範例)
– 大型語言模型的長期記憶與外部知識庫整合原理
– 向量資料庫在對話系統中的應用與最佳實踐
– 使用者資料隱私與資料治理在對話系統中的實務指南
內容說明與結語
本文在原文核心觀念的基礎上,轉寫為完整的繁體中文文章,並加入背景解釋、設計原則與實作要點,旨在提供讀者清晰可操作的方向,使 CrewAI 的代理能在跨會話間保留有用的知識與偏好,提升對話連貫性與使用者滿意度。全文保持客觀、中性語調,避免不必要的技術繁瑣細節,同時提供實務落地的步驟與風險考量,協助開發團隊在短時間內完成持久記憶的初步實作。

*圖片來源:Unsplash*