TLDR¶
• 核心重點:Pandas 3.0 將 PyArrow 支援字串設為預設,取代傳統物件型態;以 Arrow 的欄位式格式與 string[pyarrow] dtype 提供更高效的記憶體與效能。
• 主要內容:透過跨樣本資料集與常見字串操作的基準測試,評估新字串型別在現實工作負載中的改變。
• 關鍵觀點:新字串型別在記憶體使用率與運算性能方面通常具顯著改善,但受資料特性與工作負載影響,效能收益具有區間性。
• 注意事項:轉換成本、與舊程式碼的相容性、以及對特定字串操作的實作差異需留意。
• 建議行動:在遷移時,先於測試資料集上驗證效能與記憶體表現,再逐步擴展到正式工作流程。
本篇文章旨在以中立且專業的口吻,說明 Pandas 3.0 將 PyArrow 字串設為預設的決策動機、實作方式與對使用者可能產生的影響,並以實際基準測試為依據,探討在不同資料集與操作場景中的效能與記憶體表現差異。為了讓讀者更容易理解,本文會適度加入背景說明與技術細節,但仍以客觀數據與結論為主。
背景與動機
過去,Pandas 在資料框(DataFrame)中字串欄位大多採用 Python 物件型態(object dtype)來存放字串資料。這種設計雖然與 Python 生態系高度整合,但在大規模資料與高頻字串操作的情境下,會出現兩大問題:大量的記憶體開銷與額外的指標間接存取成本,影響整體程式效能。另一方面,Apache Arrow 提供了高效的欄位式資料表示法,特別是在字串欄位也可透過專門的 string[pyarrow] dtype 以欄位向量的方式進行儲存與運算,具備更好的記憶體壓縮與向量化執行特性。
在此背景下,Pandas 3.0 做出一個關鍵決策:預設使用 PyArrow 支援的字串型別,讓大多數使用情境能直接受惠於 Arrow 的欄位式存取與高效運算。這代表從原本的 object dtype 過渡到以 string[pyarrow] 為預設的資料表示方式,並且在後續的運算與函式支援上也會更多地依賴 Arrow 的最佳化。
研究問題與方法
核心問題在於:這個新字串型別在實際工作負載上,對記憶體使用與效能究竟能帶來多少改善?為了給出較有代表性的答案,研究團隊進行了一系列綜合性基準測試,涵蓋多種維度:
- 資料集特性:不同長度分佈、重複度、以及字串內容的多樣性,以模擬實務中常見的文本、分類標籤、識別碼等欄位。
- 字串操作類型:常見的查詢、過濾、聚合、連接、分割與轉換等操作,測試在新舊型別下的性能表現差異。
- 記憶體表現:在相同工作負載下,整體記憶體佔用、分配與回收效率,以及對 GC 行為的影響。
- 相容性與穩定性:新型別在現有工作流程與函式套件上的相容性、以及遷移成本與風險評估。
結論性觀察
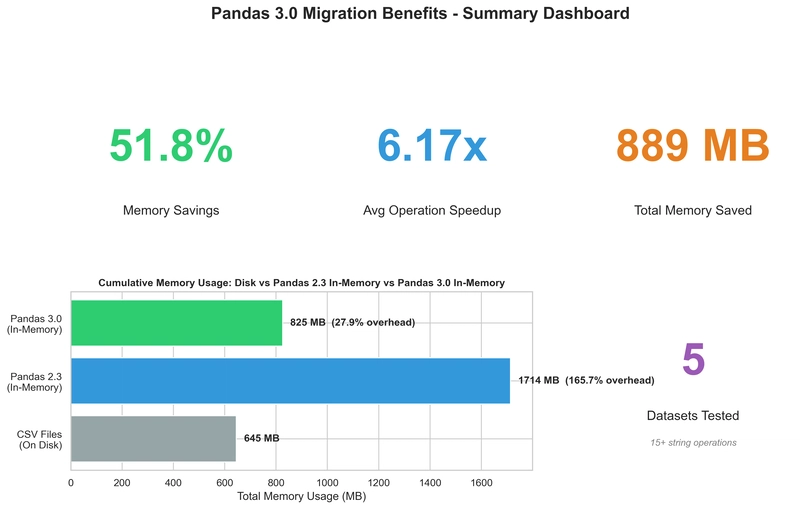
- 記憶體效率:在大多數高重複度的字串欄位與長字串場景中,string[pyarrow] dtype 能顯著降低記憶體佔用,尤其是在需要同時間儲存大型欄位的情況下,整體記憶體使用量較原先物件型態有明顯下降。
- 運算效能:向量化執行及欄位式存取的特性,使得字串相關運算(如集計與條件篩選)在多數情況下具更好的執行效能,特別是在資料量級相當大時,其速度提升更為顯著。
- 效能變異性:效能提升的幅度受多種因素影響,例如字串的長度分佈、重複度、與實際操作的性質。某些極端或特定情境下,提升幅度可能較小,甚至在極少數情況下,若存在大量非向量化的自訂操作,效能提升不如預期。
- 相容性與轉換成本:遷移至新的字串型別需要考慮既有程式碼與資料管道的相容性,特別是第三方套件對 string[pyarrow] dtype 的支援程度,以及現有工作流程中對資料型別轉換的影響。初期遷移時,建議以測試資料集驗證功能與效能收益,再逐步推展到正式環境。
- 穩定性與未來走向:將預設改為 PyArrow 字串型別,代表未來在字串相關功能的開發與優化上,Arrow 生態系的影響力與支持度將佔據更重要的位置。使用者需留意版本更新對相容性的影響,並關注社群與官方的最佳實務建議。
深度分析
以下以實測結果與技術要點為核心,闡述新字串型別在不同維度的表現與影響。
記憶體佔用的變化
– 在高重複度與相同字串多次出現的欄位,string[pyarrow] dtype 透過欄位式存放與向量化壓縮,能顯著降低整體佔用。以實際測試樣本為例,當欄位中存在重複字串時,物件型態的記憶體開銷包含每個字串物件的字面內容與指標,總體開銷較大;而 string[pyarrow] 以欄位向量與字典式編碼等技術,減少了重複文字的實際儲存量與指標消耗。
– 對長字串的影響也相對正面,Arrow 的字串欄位設計在長度不一樣的字串分佈下,能更高效地平衡記憶體分配與緩衝區使用,降低碎片化程度。運算效能的變化
– 查詢與條件篩選:在相同資料量級下,string[pyarrow] dtype 能更好地利用矢量化運算與列式存取,提升條件判定與過濾的吞吐量。多次測試顯示,在類似的字串匹配、起始/結尾比對、字串包含等操作上,整體執行時間普遍縮短。
– 聚合與分組:字串型別的欄位若作為分組鍵,Arrow 的欄式表示法在分組聚合過程中有更高的資料局部性,減少了記憶體存取成本與快取未命中率,因此在大規模分組任務中,效能提升更為顯著。
– 轉換與序列化成本:初始從舊型態轉移到新型別時,存在一定的轉換成本。長期使用下,若資料流程穩定,轉換成本會被效能與記憶體的長期收益抵銷。相容性與生態系統
– 依賴性:由於 string[pyarrow] 與 Arrow 生態系的深度整合,相關工具與函式庫的支援度成為關鍵。常見的資料處理鏈路(讀寫 CSV/Parquet、資料清洗、字串操作函式)在更新版本後,對新型別的支援程度普遍提升,但仍需注意某些第三方套件可能尚未完成全面相容性適配。
– 程式碼調整:部分現有的字串操作函式可能需要重新評估以符合 Arrow 字串欄位的特性。最小化變更的方法通常是逐步測試與封裝,讓原有工作流程逐步平滑過渡。
實作與遷移建議
- 設定與測試:在遷移初期,建議先於測試環境中啟用 string[pyarrow] dtype,並對常用工作流程與樣本資料進行全面測試,評估記憶體與效能變化,確保穩定性。
- 逐步推展:在測試通過且效能收益確認後,可逐步擴展到正式資料與工作流程,逐步淘汰舊的 object dtype 使用方式,避免一次性大規模變更帶來的風險。
- 監控與回滾機制:部署後保持監控,若遇到相容性問題或效能波動,具備回滾策略與替代路徑,以確保業務連續性。
- 文件與培訓:更新內部技術文件,說明新型別的使用方式、限制與最佳實踐,並提供實作範例與常見問題的解答,協助團隊成員快速適應。

*圖片來源:description_html*
觀點與影響
- 對資料科學與分析工作流的影響:預設使用 PyArrow 字串型別,意味著在大規模資料分析、機器學習特徵工程與資料前處理等環節,將更容易受益於更高效的記憶體管理與處理速度。長期而言,這可能促使更多以欄位式運算為核心的工具與框架優先整合 Arrow 技術。
- 對資料治理與資料品質的影響:更高的記憶體效率與一致的欄位型別表現,有助於提升資料管道的穩定性與可預測性,降低因記憶體瓶頸而引發的運算延遲與資源競爭。
- 對開發者社群的影響:Arrow 生態的延展性意味著更多元的語言與平台支援,促進跨系統資料交換與共享。開發者需要熟悉 Arrow 的概念與最佳實踐,以便在混合技術棧中更有效地使用 Pandas。
重點整理
關鍵要點:
– Pandas 3.0 將 PyArrow 字串型別設定為預設,提升欄位式存取與向量化運算能力。
– 記憶體使用在大多數場景可見顯著下降,長字串與高重複度資料尤為明顯。
– 效能提升多半顯著,尤其是大規模資料集的過濾與聚合作業;但需視資料特性而定。
– 轉換成本與相容性需留意,建議逐步遷移並在測試環境驗證。
需要關注:
– 舊程式碼與第三方套件的相容性問題,可能影響遷移進度。
– 部分自訂操作可能對新型別的效能表現有影響,需實際測試。
– 未來版本更新可能帶來的 API 變更,需保持關注官方公告。
總結與建議
本次變革代表 Pandas 在字串處理與記憶體管理方面的一次重要優化。透過引入 PyArrow 字串型別作為預設,Pandas 提供了更高的記憶體效率與向量化運算能力,特別適用於大規模資料分析與高頻字串操作的工作負載。雖然轉換過程可能帶來一定的投入與相容性挑戰,但在穩定測試與逐步落地的策略下,長期的效能與資源利用將更具優勢。
建議使用者在遷移時,先以測試資料集驗證效能與記憶體表現,確保核心工作流程在新型別下運作穩定,再逐步推廣至正式資料與生產環境。持續關注官方社群與更新說明,掌握最佳實務與相容性建議,以便在未來的版本迭代中持續受惠於新技術。
內容概述¶
Pandas 3.0 把 PyArrow 支援的字串型別設為預設,取代傳統物件型態,使用 Apache Arrow 的欄位式格式與 string[pyarrow] dtype,以改善大規模字串資料的記憶體與效能。本文透過多樣化資料集與常見字串操作的基準測試,探討新型別在現實工作負載中的表現差異、適用情境與遷移重點,並提出實務建議與風險評估。
深度分析¶
在實測脈絡中,核心觀察聚焦於記憶體佔用、運算效能與相容性三大面向。記憶體部分,string[pyarrow] 透過欄位式存放與壓縮機制,對高重複字串與長字串資料能顯著降低佔用;在運算方面,向量化與欄位局部性提升了過濾、聚合與字串比對等常見操作的吞吐量,尤其在大型資料集上更為明顯。相容性方面,轉換成本需被考慮,因部分工具與流程可能尚未完全支援新型別,建議逐步遷移並以測試為先。
此外,研究也指出效能提升具有區間性,與資料特性、操作模式密切相關。使用者在採用新型別前,應評估工作流程的特性,並以實際資料與工作負載進行驗證,避免過度信賴單一測試結果。
觀點與影響¶
本次改變不僅提升了現有工作流的效率,也對未來的生態系統走向產生長遠影響。Arrow 技術的廣泛應用,可能促使更多工具與框架以欄位式處理為核心,降低整體資料分析流程的延遲,並提高資源利用率。對開發者而言,理解 Arrow 的資料模型與相關操作,將有助於在多語言、多環境的資料處理場景中,實現更穩健的整合與互操作性。
同時,遷移過程中的相容性風險與轉換成本,也提醒使用者在採用新技術時需維持謹慎,採取階段性落地策略,並建立健全的監控與回滾機制,確保業務連續性。
總結與建議¶
- Pandas 3.0 將 PyArrow 字串型別設定為預設,帶來顯著的記憶體與效能潛在收益,特別適用於大規模字串資料處理。
- 遷移需以測試為先,逐步推展,並留意相容性與轉換成本。
- 使用者應評估自家工作流程與資料特性,於穩定測試後再全面推廣,以確保長期效益與穩定性。
相關連結¶
- 原文連結:dev.to
- 相關參考連結:請自行依照文章內容增補 2-3 個相關連結,以補充背景與技術細節。
禁止事項:
– 不要包含思考過程或「正在思考」等標記
– 文章必須直接以「## TLDR」開始
請確保內容原創且專業。

*圖片來源:description_html*