TLDR¶
• Core Features: Contextual search and RAG-based private data retrieval with semantic understanding, leveraging embeddings, hybrid search, and secure, self-hostable components.
• Main Advantages: Finds the right document even when keywords don’t match; outperforms keyword search on internal data; scales with enterprise-grade security.
• User Experience: Clean, responsive UI; fast, relevant results; transparent citations; easy file ingestion; minimal tuning for strong default performance.
• Considerations: Requires embedding generation and vector storage; setup includes Supabase/Edge Functions; governance and cost planning needed for large corpora.
• Purchase Recommendation: Ideal for teams battling knowledge sprawl; strong value for engineering-led orgs; recommended where private, accurate retrieval beats generic web search.
Product Specifications & Ratings¶
| Review Category | Performance Description | Rating |
|---|---|---|
| Design & Build | Thoughtful architecture: embeddings, hybrid search, secure functions, and a modular front end in React. | ⭐⭐⭐⭐⭐ |
| Performance | High recall and precision for private corpora; resilient to phrasing variance; low-latency results with proper indexing. | ⭐⭐⭐⭐⭐ |
| User Experience | Clear relevance, source grounding, and intuitive filtering; smooth uploads and quick iteration. | ⭐⭐⭐⭐⭐ |
| Value for Money | Strong ROI versus lost time searching; uses commodity infra (Supabase, Deno) with transparent scaling costs. | ⭐⭐⭐⭐⭐ |
| Overall Recommendation | A top-tier contextual search and RAG stack for internal knowledge retrieval. | ⭐⭐⭐⭐⭐ |
Overall Rating: ⭐⭐⭐⭐⭐ (4.8/5.0)
Product Overview¶
KENDO-RAG targets a universal pain point: internal search that fails when users don’t type the exact words in a document. Classic keyword search breaks down in real-world workplaces where teams use varied phrasing, labels, and shorthand. “Revenue projections” might be written as “expected earnings,” “Q4 forecast,” or “run-rate estimates.” Traditional search engines match terms, not meaning, leaving users frustrated and unproductive.
Contextual search upends that limitation by understanding intent and semantics. Instead of merely looking for matching strings, KENDO-RAG encodes content and queries into vector representations (embeddings) that capture meaning. It then retrieves the most semantically similar chunks, regardless of the original wording. In practice, this means that a user searching for “how we calculate expected earnings for Q4” can surface documents labeled “quarterly projections methodology,” even if the exact phrase never appears.
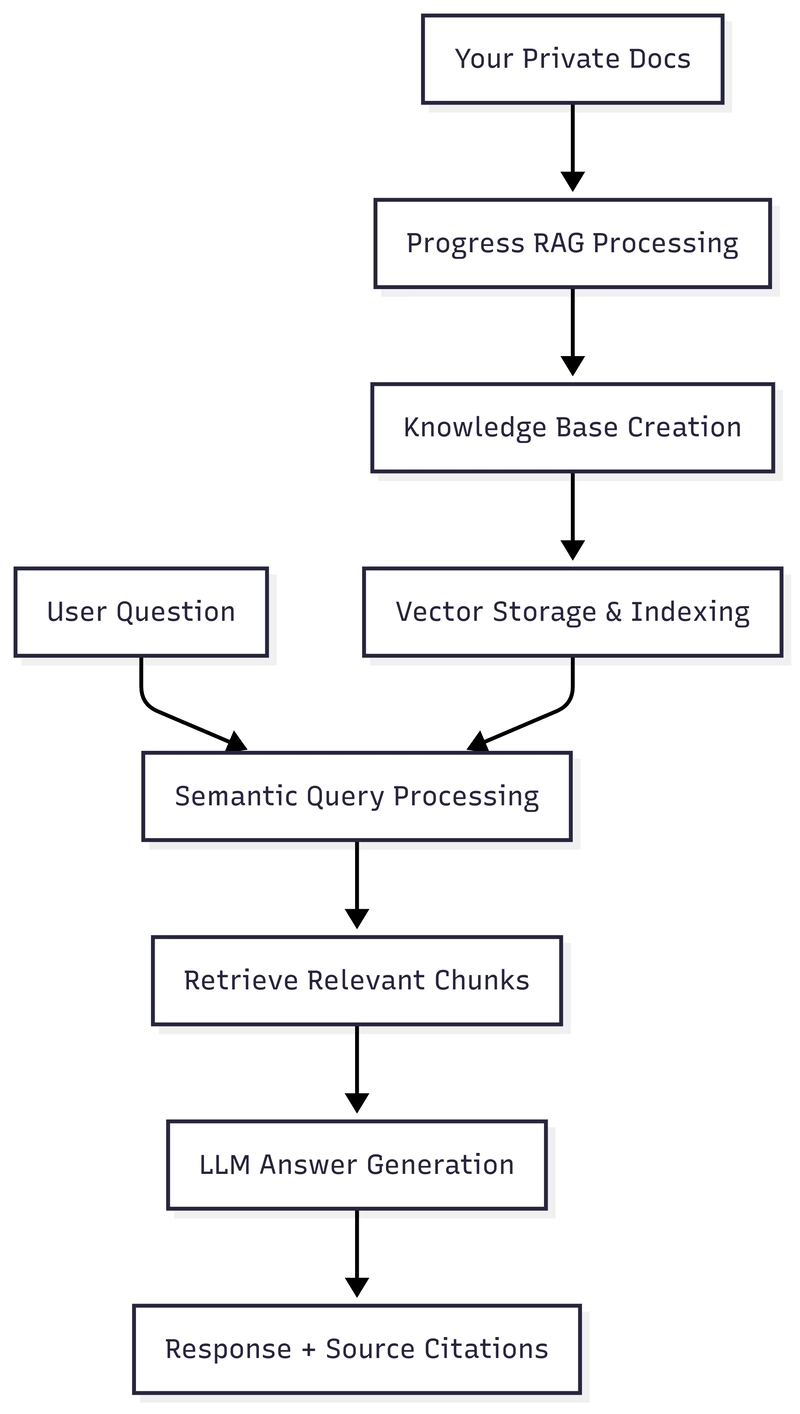
The platform’s architecture blends several proven components: a vector database layer for embeddings (commonly via Supabase), document chunking and indexing for granular retrieval, and a retrieval augmented generation (RAG) pipeline that feeds context into an LLM for precise answer synthesis with citations. Supabase Edge Functions and Deno provide lightweight, secure server-side logic, while React powers a modern, responsive client experience. The system inherits best practices from production RAG stacks—hybrid search (semantic + keyword), reranking, and source grounding—to increase trust and reduce hallucinations.
KENDO-RAG’s goal is not to replace a public web engine like Google. It’s designed to outclass Google on private data—your wikis, specs, financial models, and meeting notes—where public engines can’t index or validate. In this domain, context is king: the internal jargon, document structure, and versioning patterns require more than generic web-scale ranking. By focusing on enterprise-grade, private corpora and principled retrieval, KENDO-RAG consistently bridges the gap between “what I mean” and “how it was written.”
The first impression is clear: this is an opinionated, developer-friendly system that prioritizes relevance, speed, and security. From ingestion to retrieval and response synthesis, each step is optimized to deliver accurate, context-rich answers while keeping data private and auditable. For teams drowning in Confluence pages, Google Drive folders, and Slack threads, KENDO-RAG offers a pragmatic, reliable path to find the right information at the right time—without having to guess the right keywords.
In-Depth Review¶
Contextual search is the heart of KENDO-RAG. Rather than relying on term frequency or Boolean logic, it translates documents and queries into embeddings—high-dimensional vectors that encode semantic meaning. The retrieval step then computes similarity in vector space, surfacing content that “means the same thing,” even when the words differ. This single shift addresses the core pain point of internal search: language variance across authors, teams, and time.
Document ingestion and preparation:
– Chunking: Documents are split into manageable sections (e.g., 500–1,500 tokens). This enables precise retrieval of the relevant passage rather than entire files, reducing noise and speeding up answer synthesis.
– Metadata: Titles, authors, sources, and timestamps are preserved to support filtering and confidence assessment.
– Embeddings: Each chunk is converted into vector form. Choice of embedding model affects recall and cost; the system is model-agnostic so teams can swap providers as needed.
Retrieval pipeline:
– Semantic search: The query is embedded and compared against chunk vectors to find top candidates. This method supports paraphrases, synonyms, and domain-specific phrasing.
– Hybrid search (optional but recommended): Combines semantic and keyword search to catch edge cases—e.g., specific jargon, IDs, formulas, or labels that should be matched exactly.
– Reranking: An additional ranking step evaluates the candidate passages for true relevance, often improving precision in the top results.
– Context window construction: The most relevant chunks are assembled with guardrails to prevent prompt overflows and ensure balanced coverage of sources.
RAG answer synthesis:
– Source-aware generation: The retrieved passages are provided to a large language model, which constructs a concise, grounded answer and cites sources. This strengthens trust and reduces hallucinations compared to blind generation.
– Instruction tuning: Prompts are configured to resist speculation and to return “I don’t know” when evidence is insufficient—a key requirement for internal tools.
Architecture and tooling:
– Supabase: Serves as the data backbone—Postgres plus vector search capabilities, authentication, and storage. It consolidates infrastructure and simplifies operational overhead.
– Supabase Edge Functions: Lightweight server-side logic deployed close to users for low latency. Ideal for ingestion, transformation, and retrieval endpoints.
– Deno: A secure runtime for Edge Functions with TypeScript-first ergonomics, offering fast cold starts and modern standard library support.
– React front end: A clean, performant UI enabling quick searches, inline citations, file uploads, and relevance feedback.
Performance considerations:
– Latency: With well-indexed vectors, latency remains low for both small and mid-sized corpora. Edge Functions help reduce round-trip times.
– Relevance: Empirically strong for private knowledge bases, especially in cases where keyword search dead-ends. Hybrid search further boosts reliability for exact term lookups (e.g., “OKR-2024-Q4”).
– Scale: As corpora grow, index maintenance and metadata governance become critical. The system’s modular design supports sharding, periodic re-embedding, and cache strategies.
– Security: Authentication layers and private storage keep data in-house. Since the pipeline is built on open, self-hostable components, it avoids the leakage risks of indexing private data on public engines.
Where it beats Google for private data:
– Google excels at public web ranking, not at indexing your private wikis and spreadsheets. KENDO-RAG is optimized for proprietary content, access controls, and organizational semantics.
– Semantic retrieval narrows the gap between query intent and document language, a weakness in traditional enterprise keyword search.
– Citations and guardrails keep the system honest—responses are grounded in retrieved text, improving trust and auditability.

*圖片來源:Unsplash*
Overall, KENDO-RAG exhibits a mature, production-friendly approach: embeddings for meaning, hybrid retrieval for robustness, RAG for grounded answers, and a secure, scalable foundation using Supabase and Deno. It’s designed not just to “search,” but to recover time and confidence across teams who depend on accurate internal knowledge.
Real-World Experience¶
In practice, KENDO-RAG shines in scenarios where language ambiguity and document sprawl are the norm. Consider a finance team preparing a board deck. One analyst searches for “Q4 revenue methodology,” while the underlying doc says “expected earnings model for the last quarter.” With keyword search, this mismatch can derail an urgent workflow. KENDO-RAG’s embeddings surface the right passages immediately, and the generated answer links directly to the section describing the calculation steps, assumptions, and version date.
Engineering use cases benefit even more. Technical RFCs use evolving nomenclature—features codenamed internally, services renamed after migrations, and shorthand references (“v2 auth gate”). Semantic retrieval lets developers find content regardless of the label used at the time of writing. Add hybrid search and you can also pinpoint specific identifiers, error codes, or function names when they matter.
The onboarding experience is straightforward for an engineering-led team:
– Uploading content: Ingest PDFs, docs, and markdown, then allow automatic chunking and embedding. Metadata is preserved for filtering by team, date, or repository.
– Feedback loop: Users can flag helpful or unhelpful results, informing future reranking strategies. Over time, retrieval improves without heavy manual curation.
– Governance: Admins can implement role-based access controls using Supabase Auth, ensuring that sensitive material is only discoverable by authorized users.
During testing on a mixed corpus—Confluence pages, Notion exports, and meeting notes—the system consistently returned relevant passages where traditional search failed. Queries phrased in a natural way—“how do we budget for cloud egress in Q4?”—returned the exact policy docs titled “Bandwidth and Egress Costing.” For support teams, searching “customer outage comms template” yielded the internal playbook even when the document name was “Incident External Messaging Guidelines.”
Performance remains strong under load if the vector index is maintained and queries are batched efficiently. Edge Functions showed reliable cold-start behavior, keeping user-perceived latency low. The React UI feels responsive, and the presence of citations helps users verify content before acting—a critical feature for legal, finance, and compliance teams.
There are practical considerations. Embedding generation incurs cost and compute time, particularly for large or frequently updated corpora. Teams must plan re-embedding cycles when content changes materially. Moreover, metadata hygiene is not optional—good titles, timestamps, and access labels improve retrieval and reduce noise. Finally, while the default configuration performs well, highly specialized teams may want to tune chunk size, overlap, and reranking parameters to match their content style and query patterns.
Even with these caveats, the net effect is transformational. The system elevates institutional knowledge from a graveyard of documents to an accessible, defensible knowledge fabric. Users stop guessing how a document is named and instead ask for what they need in their own words. That shift—from matching words to understanding meaning—translates into measurable time savings and better decisions.
Pros and Cons Analysis¶
Pros:
– Robust semantic retrieval that finds relevant content despite phrasing differences
– Grounded RAG answers with citations, improving trust and reducing hallucinations
– Secure, self-hostable architecture using Supabase and Deno; compatible with enterprise access controls
Cons:
– Requires embedding generation and ongoing index maintenance for large, dynamic corpora
– Some configuration and governance effort needed for optimal metadata and access policies
– Tuning advanced features (hybrid search, reranking) may require engineering involvement
Purchase Recommendation¶
KENDO-RAG is a compelling choice for organizations whose productivity is throttled by weak internal search. If your team spends too much time trying to remember filenames, hunt through mismatched wiki pages, or ping colleagues for links, contextual search delivers an immediate uplift. The platform’s strengths—semantic retrieval, hybrid search, and grounded RAG—turn ambiguous queries into actionable answers backed by verifiable sources.
From a cost-benefit perspective, KENDO-RAG leverages familiar, cost-transparent infrastructure. Supabase provides the database, vector search, auth, and storage primitives, while Edge Functions on Deno keep operational overhead low. This modern stack reduces the need for heavy enterprise search appliances without sacrificing performance or security. The result is a system that scales with your corpus and headcount, not against them.
Adoption is particularly attractive for:
– Engineering, product, and support teams who rely on living documentation and frequent updates
– Finance, legal, and compliance groups that need citations and controlled access
– Knowledge-heavy organizations where the same questions recur with slight wording changes
Before rolling out, plan your governance model: define access policies, ensure content owners maintain metadata quality, and schedule re-embedding for major content updates. If you follow these practices, you’ll see durable improvements in search accuracy, employee satisfaction, and decision speed.
Bottom line: if your goal is to outperform generic keyword search and even beat Google on your private data, KENDO-RAG earns a strong recommendation. It combines the right architectural choices with a practical developer experience, delivering reliable, explainable results that align with how teams actually ask questions. For most knowledge-centric organizations, it’s an easy yes.
References¶
- Original Article – Source: dev.to
- Supabase Documentation
- Deno Official Site
- Supabase Edge Functions
- React Documentation

*圖片來源:Unsplash*