TLDR¶
• 核心重點:在資料驅動的設計環境中,缺乏標準化的個人化 UX 實作方法,本文提出以「個人化金字塔」為框架。
• 主要內容:透過多層次設計與資料治理,建立可重複、可測量的個人化 UX 方案。
• 關鍵觀點:專注於使用者需求與資料品質之間的平衡,避免過度個人化與隱私風險。
• 注意事項:需清楚界定資料來源、授權邊界與負責任的使用方式。
• 建議行動:先建立資料準則與治理流程,再逐步落地各層級的個人化策略與度量。
內容概述¶
在當今「資料驅動」的使用者體驗(UX)設計場景中,設計師常被要求提供個人化的數位體驗,無論是公眾網站、使用者入口網站,或是原生應用程式。儘管行銷界對個人化平台的炒作層出不窮,實際上在實作層面,仍缺乏統一且可操作的標準方法來落實個人化 UX。這使得團隊在落地階段往往遇到技術、倫理、與使用者接受度的多重挑戰。
本文章提出一種「個人化金字塔」的設計框架,旨在協助 UX 專業人員在資料驅動的環境中,建立可重複、可評估的個人化策略。經過過去數年的多個個人化專案實作經驗,作者整理出一套清晰的分層設計原則,以因應不同層面的需求與風險。
為了讓中文讀者更容易理解,本文將從框架概念、實作原則、治理機制、測量與驗證、以及實務案例等面向,進行詳盡說明,並在最後提供可操作的行動清單。整體語氣保持中立與專業,避免誇大或過度保證效果。
深度分析¶
個人化框架的核心在於將龐大的使用者資料與多樣的體驗需求,透過層次化的設計逐步落地。金字塔的底層關注基礎資料與信任基礎,向上逐步過渡到情境化與個人層面的體驗調整,最上層則聚焦於長期的效果評估與持續優化。具體而言,主要分為以下幾個層次與原則:
1) 資料治理與信任基礎
– 資料品質與可用性:建立資料清單、元資料與資料品質監測機制,確保可用於個人化的資料具備可追溯性與穩定性。
– 隱私與授權框架:在設計前定義可用的資料類型、使用範圍與使用期限,確保符合法規與倫理標準,並提供使用者透明的控制機制。
– 設計與工程的協同:透過跨職能團隊,確保資料治理與 UX 設計需求之間的對齊,降低風險與技術債。
2) 情境化與角色化的位階
– 情境化層級:根據使用情境(例如特定任務、時間、地點)提供相關的內容與互動,而非全域性全量個人化。
– 角色化與分群策略:以最小可行單位的個人化為起點,例如針對特定使用者群體提供平均化的最佳化方案,逐步過渡到個別化程度的提升。
3) 內容與介面層的適配
– 內容動態化與可組裝性:將內容模組化,便於在不同情境下自動拼接與呈現,提升效率並降低維護成本。
– 介面動作與導覽的調整:根據情境與使用者需求,動態調整導覽路徑、功能顯示與操作順序,提升易用性與效率。
4) 衡量與驗證
– 指標設計:建立與目標一致的度量指標,如使用者完成任務的成功率、時間成本、轉換率、留存等,並設定合理的基準與容忍度。
– 實驗與迭代:以 A/B 測試、分群測試等方法驗證個人化策略的效果,並以實證結果驅動優化。
5) 風險管理與道德考量
– 避免過度個人化與回避「冷知識」的風險:過度推送可能造成使用者疲乏,適度留白與預設保留選項是必要的。
– 公平性與可及性:確保個人化不造成新的偏見或顯著的跨群體差異,並兼顧各群體的可及性。
在實務操作層面,建議以「金字塔自上而下」的方式規劃與落地:理解最需要的資料類型與風險點、設計情境化與分群策略、再到建立可重複的內容與介面模組,以及以科學方法進行評估與調整。這樣的流程有助於建立穩健的個人化系統,並降低在快速迭代中出現的倫理與法規風險。

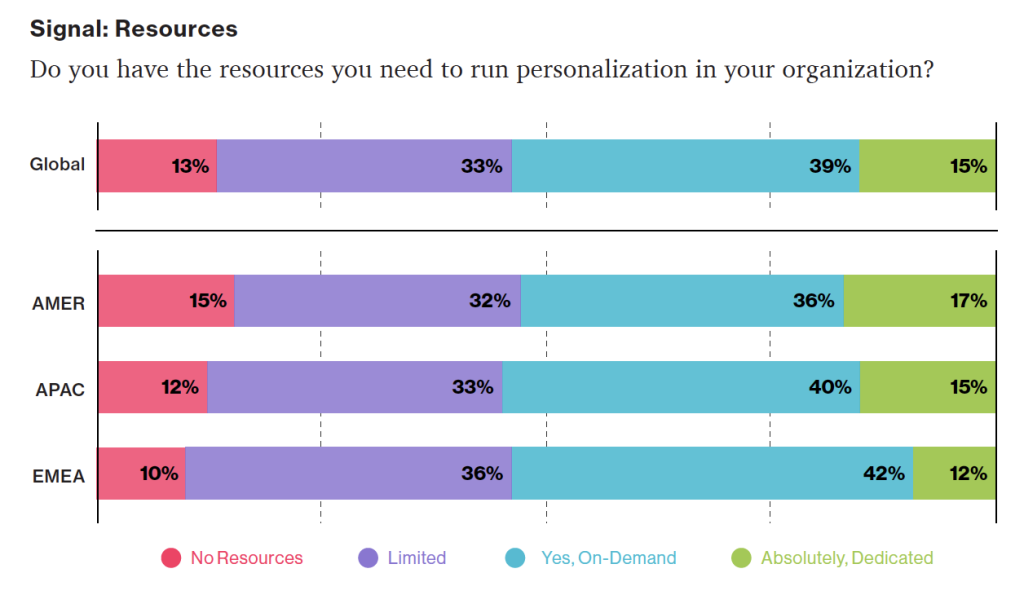
*圖片來源:description_html*
此外,作者也強調,在設計與實作過程中,必須讓團隊中的設計師、資料科學家、工程師、法務與風險管理人員保持開放的溝通,建立共識與可追溯的決策記錄,確保每個層級的選擇都有充分的理由與證據支撐。只有在這樣的多方協作下,才可能讓個人化 UX 的實踐真正落地,而非僅停留在理論與口號之間。
觀點與影響¶
個人化 UX 的長遠影響在於提升使用者的滿意度與任務完成效率,同時也帶來對資料治理與倫理標準的更高要求。若缺乏清晰的治理與透明度,個人化或許會演變為「過度推送」或「黑盒決策」,造成使用者信任下降甚至法規風險。金字塔框架的價值在於提供結構化、可控的路線,使企業能在技術與設計間取得平衡,逐步提升個人化的深度與廣度,同時保護使用者隱私與自主權。
長期而言,這樣的框架也可能推動行業標準的形成,促使更多組織建立統一的資料治理、倫理審查與測量方法。對使用者而言,合理的個人化能提升工作效率、減少學習成本與提高互動的相關性;對企業而言,則可能提高轉換率、用戶留存與品牌信任度。當然,前提是框架被妥善實施,並持續以資料驅動的證據回饋設計決策。
重點整理¶
關鍵要點:
– 建立資料治理與信任基礎,確保資料品質與使用透明度。
– 以情境化與分群策略為起點,逐步推進個人化深度。
– 內容與介面模組化,提升可重用性與維護性。
– 以科學方法衡量效果,透過實驗迭代改進。
– 考量倫理、隱私與公平性,避免過度個人化與偏見。
需要關注:
– 資料來源授權與使用範圍的界定是否明確。
– 使用者對個人化程度的接受度與控制權。
– 法規風險與公司風險管理的落地執行力。
總結與建議¶
在資料驅動的設計時代,個人化不再是「花俏功能」的代名詞,而是需要以治理、情境、模組化內容與嚴謹驗證為基礎的系統性實踐。透過「個人化金字塔」的分層設計,團隊能更清楚地掌握每一階段的需求與風險,從資料品質與授權治理開始,逐步落地到情境化與個別化的實作,並以科學的方法測量與優化成效。這樣的路徑不僅有助於提升使用者體驗,亦有助於維護使用者信任與公司長遠的競爭力。
在實務層面,建議企業先建立清晰的資料治理與倫理審查流程,明確定義可用的資料類型、使用情境與時效,並設置可觀察的指標與報告機制。接著以最小可行的個人化策略開始,確保在早期就能取得可驗證的成果,再逐步擴展至更高層次的情境化與個人化。
最後,跨職能團隊的協作不可或缺。設計師、資料科學家、工程師、法務與風險管理人員應共同參與決策,維護透明度與可追溯性,讓個人化 UX 的實踐在倫理與效果之間找到平衡點。
相關連結¶
- 原文連結:https://alistapart.com/article/personalization-pyramid/
- 根據文章內容添加的相關參考連結:
- 企業資料治理與個人化實務指南
- UX 設計中的倫理與隱私考量
- 資料驅動設計的實驗與測量方法

*圖片來源:description_html*