TLDR¶
• Core Points: Traditional round-robin load balancing wastes GPU cycles by racing models; a token-aware balancer can preselect the most suitable backend, improving efficiency and latency.
• Main Content: The article explores moving from race-based load balancing to a token-aware approach that assigns tasks to the most appropriate model upfront, reducing waste and speeding up responses for large language model (LLM) workloads.
• Key Insights: Model selection should consider token streams and workload characteristics; dynamic routing can optimize throughput and resource utilization without sacrificing accuracy.
• Considerations: Implementing token-aware routing requires reliable model profiling, accurate latency and cost metrics, and safeguards against misrouting due to distributional shifts or model drift.
• Recommended Actions: Design and deploy a token-aware load balancer, instrument end-to-end tracing, maintain model performance profiles, and continuously validate routing decisions against real user demands.
Content Overview¶
Traditional load balancing for LLM ensembles often relies on a simple, race-based strategy: send the same user prompt to multiple models in parallel and return the first response. This “best of” approach tends to improve perceived latency because users receive a result quickly, but it comes at a high cost. Each request triggers multiple models to run simultaneously, consuming GPU cycles across several servers. The wasted computation not only increases operational costs but also accelerates hardware degradation and energy usage. In practice, this approach can be particularly wasteful for longer or more complex prompts where the benefit of racing diminishes as model performance converges.
The central question then arises: can we do better than racing backends? If a load balancer could select the most suitable backend from the outset, could we reduce unnecessary computation while maintaining or even improving response times? The article delves into a token-aware load balancing paradigm designed for LLM inference workloads, aiming to align backend choices with the evolving nature of the conversation and the characteristics of the prompt.
Why traditional load balancing falls short for LLM workloads
– Uniform distribution versus workload-aware routing: Traditional load balancers aim to distribute requests evenly or minimize tail latency using generic metrics. However, LLM tasks exhibit variability in token demand, context length, and required capabilities (e.g., coding, reasoning, multilingual support). A one-size-fits-all distribution often results in suboptimal performance, with certain models underutilized for some tasks and overburdened for others.
– Latency versus throughput trade-offs: Racing models can reduce latency for some prompts but at the cost of running multiple models in parallel, inflating compute costs. For many user scenarios, consistently fast and cost-efficient responses depend on selecting a model that aligns with the prompt’s intent and complexity.
– Resource and cost implications: Inference on large models is expensive. Running several models in parallel for every request multiplies resource usage and energy consumption, which may not be sustainable at scale.
Towards a token-aware approach
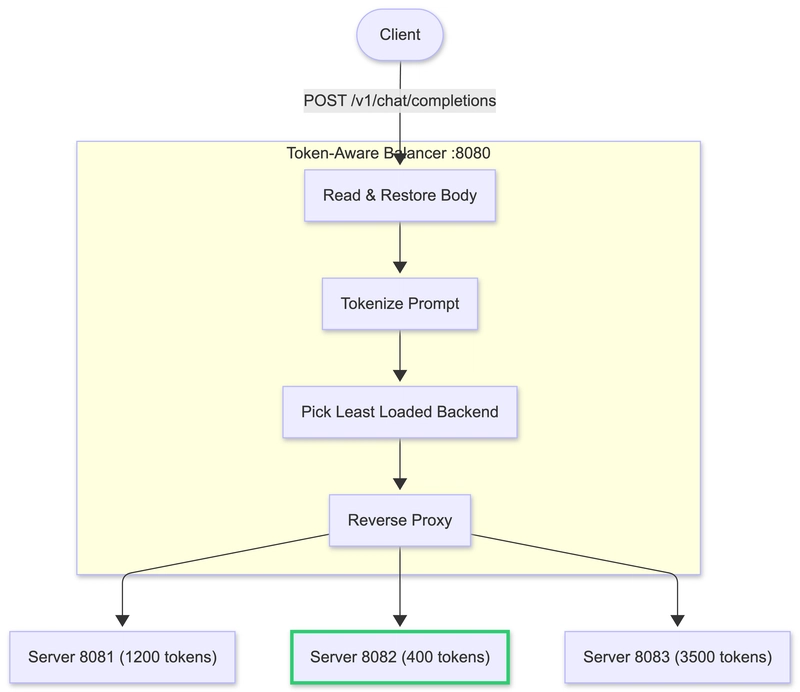
The proposed paradigm shift focuses on routing decisions informed by the tokenized discourse of the prompt and the current state of each model. Rather than broadcasting a request to many models, the system evaluates: which model is most likely to generate the best answer within the desired latency and cost envelope given the prompt’s token budget, the user’s expectations, and the model’s strengths. By anticipating which model will perform best for a given token trajectory, the balancer assigns the task upfront, avoiding unnecessary multi-model execution.
Key components of a token-aware load balancer
– Model profiling and capability mapping: Build a catalog of each model’s strengths, latency, memory footprint, and typical token efficiency. This catalog should be kept up to date as models evolve or as new models are added.
– Prompt and user context embedding: Extract features from the incoming prompt and any available user context to estimate the complexity, domain, and required capabilities. This informs routing decisions.
– Token-budget-aware routing: Consider the expected token length of the response and the total tokens involved in the prompt to estimate wall-clock latency and cost for each candidate model.
– Dynamic routing policies: Use policy mechanisms that can adapt to changing workloads, model drift, and evolving performance metrics. Policies should balance latency targets, cost thresholds, and fairness among models.
– Observability and feedback loops: Instrument end-to-end latency, token utilization, and accuracy signals. Use this data to update model profiles and routing rules continuously.

*圖片來源:Unsplash*
Benefits of token-aware routing
– Efficiency gains: By selecting the most appropriate model at the outset, you reduce wasted computation from parallel, multi-model executions.
– Predictable latency: Routing decisions informed by token budgets and model performance can yield more consistent response times.
– Cost optimization: Fewer models running per request translates to lower operational costs, particularly at scale.
– Better resource utilization: Models with complementary strengths can be scheduled based on the task, leading to improved overall system throughput.
Challenges and considerations
– Accurate profiling: Keeping model performance profiles current is essential. Model drift, updates, or changes in workloads can render profiles outdated.
– Feature extraction reliability: The system must reliably infer prompt complexity and user intent without introducing biases that misroute requests.
– Cold-start and new models: Integrating new models requires initial profiling and calibration to avoid initial misrouting.
– Robustness to distributional shift: Real-world usage varies; routing policies must adapt to shifts in the task mix without compromising quality.
– Safety and compliance: Ensure routing decisions do not inadvertently expose sensitive data or create policy violations across model boundaries.
Operationalizing token-aware load balancing
– Data-driven decisioning: Start with a baseline mapping of common task categories to preferred models, then expand with data-backed refinements as you collect more usage data.
– A/B testing and staged rollouts: Validate routing changes with controlled experiments to quantify latency, cost, and quality impacts before full deployment.
– Observability stack: Implement end-to-end tracing that captures prompt attributes, routing decisions, model outputs, latency, and token counts. Use dashboards to monitor KPIs such as average latency, tail latency, cost per request, and model utilization.
– Safety nets: Maintain a fallback mechanism to re-route or gracefully handle failures when a selected model underperforms or becomes unavailable.
– Governance and governance: Establish policies for model selection fairness and ensure compliance with data handling and privacy requirements across models.
Future implications for LLM infrastructure
Token-aware load balancing represents a step toward more intelligent, resource-conscious orchestration of AI inference ecosystems. As models grow in size and as organizations deploy diverse capabilities, the ability to map prompts to the right model in real time will become a critical differentiator. This approach aligns with broader trends in adaptive systems: dynamically tuning routing and resource allocation based on input characteristics and system state, rather than relying on static, one-size-fits-all strategies.
The shift from race-based to token-aware routing mirrors a larger evolution in cloud and edge computing: embracing task-specific optimization over uniform distribution. It invites researchers and practitioners to rethink not only load balancing but also model management, billing models, and the architectural patterns that support reliable, scalable, and cost-effective AI services. As with any optimization, the benefits depend on careful design, continuous measurement, and disciplined iteration.
Key Takeaways
Main Points:
– Racing multiple models on every request is inefficient for scalable LLM deployments.
– Token-aware load balancing seeks to assign each task to the most suitable model upfront.
– Profiling, observability, and adaptive policies are essential to success.
Areas of Concern:
– Maintaining accurate, up-to-date model profiles in a dynamic environment.
– Ensuring routing decisions generalize across diverse usage patterns.
– Balancing latency, cost, and quality without introducing routing biases.
Summary and Recommendations
A token-aware load balancer offers a pragmatic path to more efficient, scalable LLM hosting. By preselecting the best backend for each prompt based on token budgets, task characteristics, and real-time system state, organizations can reduce wasted GPU cycles, lower costs, and achieve more predictable latency. Implementing this approach requires robust model profiling, reliable feature extraction from prompts, and a strong observability framework. Start with a conservative, data-driven rollout: define clear routing rules for common task classes, instrument end-to-end tracing, and validate improvements through controlled experiments. As models and workloads evolve, continuously refine profiles and policies to sustain performance gains and maintain quality of service.
References¶
- Original: https://dev.to/sivagurunathanv/-beyond-round-robin-building-a-token-aware-load-balancer-for-llms-29i7
- Add 2-3 relevant references based on article content:
- [Relevant reference on dynamic routing for ML inference systems]
- [Reference on observability and tracing for AI services]
- [Reference on model management and profiling in multi-model deployments]
Forbidden:
– No thinking process or “Thinking…” markers
– Article starts with “## TLDR”

*圖片來源:Unsplash*