TLDR¶
• Core Points: Streaming engines solved continuous computation on unbounded data, but introduce operational complexity; SQL on Kafka can be viable without a dedicated streaming engine.
• Main Content: The trade-offs between using established streaming platforms and direct SQL-on-Kafka approaches, including deployment, maintenance, and reliability considerations.
• Key Insights: Operational costs and cluster governance are central concerns; organizations weigh ease of use, consistency, and scalability when choosing approaches.
• Considerations: Data integrity, fault tolerance, latency needs, and operational expertise influence decision-making.
• Recommended Actions: Assess existing infrastructure, pilot SQL-on-Kafka for specific workloads, and compare total cost of ownership against streaming engines.
Product Specifications & Ratings (N/A)¶
Content Overview¶
The emergence of stream processing platforms marked a shift in how organizations handle continuous computation over unbounded data streams. Technologies such as Flink, ksqlDB, and Kafka Streams enabled users to run SQL-like queries directly against event streams, eliminating much of the custom consumer development that had become a bottleneck in real-time analytics. By offering declarative APIs and familiar SQL constructs, these systems lowered the barrier to performing real-time analytics on streaming data.
However, while streaming engines deliver powerful capabilities for continuous processing, they also introduce notable operational costs. Documentation from organizations like Confluent highlights several deployment and operational challenges associated with these platforms. For example, Flink deployments can be intricate, with complexities surrounding tuning performance, managing cluster resources, and addressing issues like checkpoint failures. In practice, teams often report increased maintenance overhead, requiring specialized expertise to keep the system reliable at scale. As a result, some organizations reconsider the balance between the benefits of native streaming engines and the resources required to operate them efficiently.
This tension has prompted a closer look at alternatives that leverage Kafka data without committing to a full-fledged streaming engine. The central question is whether SQL on Kafka data can deliver the necessary real-time insights with simpler operational requirements. Proponents argue that, for certain workloads, direct SQL queries against Kafka topics—potentially complemented by lightweight processing or materialized views—can provide timely analytics with reduced complexity and cost. Critics, however, warn that bypassing a streaming engine may omit essential features such as exactly-once processing guarantees, robust state management, and advanced fault tolerance that streaming platforms typically offer.
As organizations evaluate their options, they consider several factors: the specific latency and throughput needs, the scale of the data, the maturity of the existing data architecture, and the internal expertise available for maintaining streaming infrastructure. The choice is rarely binary; many teams adopt hybrid approaches, using streaming engines for complex event processing and windowed aggregations while leveraging Kafka’s core capabilities for simpler, low-latency queries or for targeting particular data substrates without the overhead of a full streaming stack.
This article delves into the discourse around whether SQL-on-Kafka data can fulfill requirements without a dedicated streaming engine, examining the operational costs, reliability considerations, and strategic implications. It aims to provide a balanced view that informs decision-makers about the trade-offs involved in moving away from or adopting a streaming-centric architecture.
In-Depth Analysis¶
Streaming engines emerged to address a fundamental need: performing continuous computations over data that arrives indefinitely. In practice, this means aggregating, filtering, transforming, and enriching data in real time, as events stream through systems like Kafka. Flink, ksqlDB, and Kafka Streams popularized the idea of writing SQL-like queries or declarative specifications over event streams, enabling data teams to express complex processing logic without writing custom Java, Scala, or Python consumers.
The allure of this approach is clear. It reduces development time, promotes portability of skills (SQL familiarity), and offers a framework for continuous queries that evolve with business needs. In environments where event streams drive critical decisions—fraud detection, monitoring, real-time dashboards, or operational analytics—the ability to define continuous queries, handle late-arriving data, and maintain state across events becomes highly valuable.
Yet the operational reality of running a streaming engine is non-trivial. Flink, in particular, is a feature-rich system designed for fault-tolerant, stateful stream processing at scale. While its capabilities can be transformative for large-scale data pipelines, it requires careful consideration around deployment topology, resource provisioning, and governance. Tuning performance across a cluster, diagnosing checkpoint failures, and ensuring stability during upgrades can demand specialized expertise. Documentation and practitioner reports frequently highlight that the operational burden scales with data volume, feature usage, and the complexity of stateful operations.
From a cost perspective, the total cost of ownership (TCO) for streaming engines encompasses more than just compute resources. It includes administrative requirements, monitoring and alerting, disaster recovery planning, and ongoing optimization of state backends and checkpoint semantics. For teams without mature DevOps practices or with constrained engineering bandwidth, these costs can be meaningful, influencing the decision to lean on alternative approaches that deliver required insights with less operational overhead.
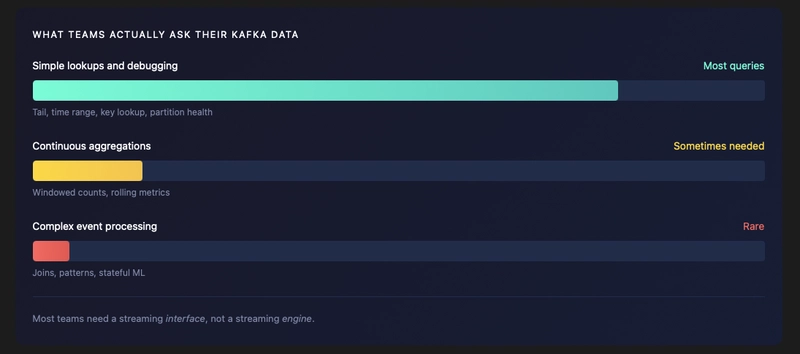
One line of inquiry centers on SQL-on-Kafka as an alternative to a streaming engine. In this approach, teams query data directly from Kafka topics using SQL-like interfaces or lightweight processors, often bypassing the need for full stateful processing pipelines. The appeal lies in reducing architectural complexity and accelerating time to insight by avoiding the additional layer of a streaming engine. However, this approach is not without trade-offs. While SQL-on-Kafka can be suitable for straightforward, near-real-time analytics, it may not automatically provide the robust guarantees and capabilities that streaming engines offer. In particular, guarantees around exactly-once semantics across distributed state, intricate windowing, and sophisticated fault tolerance patterns may be harder to guarantee without the engine’s built-in features.
The decision to rely on SQL-on-Kafka versus deploying a streaming engine depends on several dimensions. Latency sensitivity, consistency requirements, data volume, and the need for complex stateful processing are central considerations. For organizations with simpler streaming needs or with a preference to minimize operational complexity, SQL-on-Kafka can be a pragmatic option. It can enable teams to leverage their existing SQL skills and maintain a leaner architectural footprint, at least for a subset of use cases. Conversely, for large-scale, mission-critical streaming workloads that demand rigorous state management, guaranteed processing semantics, or advanced windowing logic, a streaming engine may still be the more appropriate long-term investment.
Another important factor is ecosystem alignment and toolchain compatibility. Streaming engines often integrate deeply with the broader data infrastructure, offering connectors, monitoring, and governance features designed to support enterprise data platforms. They can provide unified semantics across batch and streaming workloads, which simplifies cross-domain analytics and experimentation. In environments where governance, lineage, and reliability are prioritized, these aspects can be decisive.
The industry landscape also reflects a shift toward more flexible architectures that combine multiple technologies to achieve specific goals. Teams may use a streaming engine for complex, stateful transformations and windowed aggregations while employing SQL-on-Kafka techniques for lightweight, low-latency views or for ad-hoc analysis that does not require full continuity-of-processing guarantees. Hybrid approaches can deliver the best of both worlds but require careful orchestration to maintain consistency and avoid duplicating effort.

*圖片來源:Unsplash*
In analyzing whether SQL on Kafka data can render a separate streaming engine unnecessary, it is crucial to set clear failure scenarios and performance expectations. Streaming engines are designed to handle fault tolerance through mechanisms such as checkpoints and exactly-once processing policies, which can be critical for certain financial, healthcare, or operational uses. If a business requirement centers on deterministic processing outcomes, end-to-end traceability, and robust state management, reliance solely on SQL-on-Kafka may introduce risks that must be mitigated through compensating controls, testing, and monitoring.
On the other hand, for teams with smaller-scale streaming requirements or constrained resources, SQL-on-Kafka can offer a lean path to real-time insights. It enables rapid iteration, reduces operational complexity, and allows organizations to validate use cases before investing in a heavier streaming-layer strategy. The final decision should be grounded in a thorough assessment of the workload characteristics, reliability requirements, and long-term maintenance expectations.
In summary, the ongoing discussion about SQL on Kafka data versus traditional streaming engines reflects a broader tension between capability and complexity. Streaming engines deliver powerful, stateful processing with strong guarantees, but at a cost that may be prohibitive for some teams. SQL-on-Kafka approaches provide a simpler, potentially more cost-effective route for certain analytics workloads, while leaving room for future integration with streaming platforms as needs evolve. Organizations are advised to adopt a measured, data-driven approach, starting with precise problem statements, pilot projects, and a clear understanding of the trade-offs involved.
Perspectives and Impact¶
Looking ahead, several trends are shaping how teams approach real-time data processing and analytics. First, the demand for real-time insights continues to grow across industries—from finance and e-commerce to telecommunications and manufacturing. This drives interest in simpler, faster paths to get insights from streaming data without incurring heavy operational burdens. Second, the ecosystem around Kafka and its related tooling is maturing, with improvements in connectors, governance features, and tooling that reduces the friction of building real-time analytics pipelines. This maturation creates opportunities to experiment with SQL-on-Kafka patterns in controlled, incremental ways.
Third, there is increasing appreciation for hybrid architectures. Rather than choosing a single solution, organizations are aggregating capabilities to serve different parts of the data stack. For some teams, a streaming engine remains the backbone for complex event processing and guaranteed processing semantics; for others, SQL-on-Kafka serves as a pragmatic layer for rapid analytics, dashboards, and lightweight transformations. This hybrid mindset aligns with real-world constraints, where teams balance speed, reliability, and cost.
From a strategic perspective, the implications extend to competency development and organizational design. Teams may invest in cross-functional skills that cover both SQL-based analytics and stream processing paradigms. Governance and observability practices become even more important as data flows traverse multiple processing layers. Clear ownership, standardized patterns for fault handling, and consistent monitoring help ensure that the architecture remains maintainable as it evolves.
The future of real-time data processing is likely to be defined by flexibility, modularity, and a greater emphasis on pragmatism. Organizations will continue to evaluate the best approach for each use case, often blending approaches to leverage strengths while mitigating weaknesses. As tooling improves and operational experiences accumulate, the line between streaming engines and SQL-on-Kafka may blur further, offering more cohesive, scalable, and manageable solutions for real-time data analytics.
Key questions for the industry include how to ensure end-to-end data integrity across heterogeneous processing layers, how to standardize monitoring and governance in hybrid architectures, and how to quantify the true cost of ownership when evaluating different streaming approaches. The answers will influence how teams design their data platforms in the coming years, emphasizing not only technical capability but also operational practicality and organizational readiness.
Key Takeaways¶
Main Points:
– Streaming engines provide powerful, stateful, fault-tolerant processing for unbounded data but bring significant operational costs.
– SQL-on-Kafka offers a leaner path for certain real-time analytics, trading off some guarantees for simplicity and speed.
– Hybrid architectures that combine streaming engines with SQL-on-Kafka patterns can balance capability with practicality, depending on use case requirements.
Areas of Concern:
– Exactly-once processing guarantees and robust state management may be harder to achieve without a streaming engine.
– Operational complexity, deployment challenges, and cluster governance remain salient considerations for large-scale deployments.
– Ensuring data compatibility and consistent semantics across heterogeneous processing layers can be difficult without standardized patterns.
Summary and Recommendations¶
The debate over whether SQL on Kafka data can obviate the need for a dedicated streaming engine hinges on the specific requirements of the workload and the organization’s capacity to manage complexity. Streaming engines offer comprehensive capability for complex, stateful, and fault-tolerant processing, but they come with substantial operational overhead that can strain teams, especially when scale increases. SQL-on-Kafka approaches provide a lighter, faster path to real-time analytics for simpler use cases, enabling teams to deliver insights with less infrastructure and administrative burden. However, they may not satisfy guarantees around exactly-once semantics or sophisticated windowing that some applications demand.
A prudent approach for many organizations is to adopt a measured, data-driven process:
– Start with a clear problem statement: define latency targets, fault tolerance needs, and stateful processing requirements.
– Pilot both approaches on representative workloads to quantify performance, reliability, and maintenance effort.
– Consider a hybrid strategy that uses a streaming engine for complex, stateful, long-running tasks while applying SQL-on-Kafka for lightweight analytics and dashboards.
– Assess total cost of ownership, including personnel, monitoring, and governance in addition to hardware and cloud costs.
– Plan for future evolution: design the architecture with flexibility to migrate workloads between approaches as requirements evolve.
By grounding decisions in the specifics of the workload and organizational capabilities, teams can select an architecture that offers the best balance of insight speed, reliability, and operational practicality.
References¶
- Original: https://dev.to/novatechflow/sql-on-kafka-data-does-not-require-a-streaming-engine-3kfe
- Additional references:
- Confluent documentation on streaming engines and operational considerations
- Apache Flink: State management, fault tolerance, and deployment guidelines
- Kafka Streams and ksqlDB documentation for SQL-like streaming capabilities
- Industry analyses on total cost of ownership for streaming architectures

*圖片來源:Unsplash*